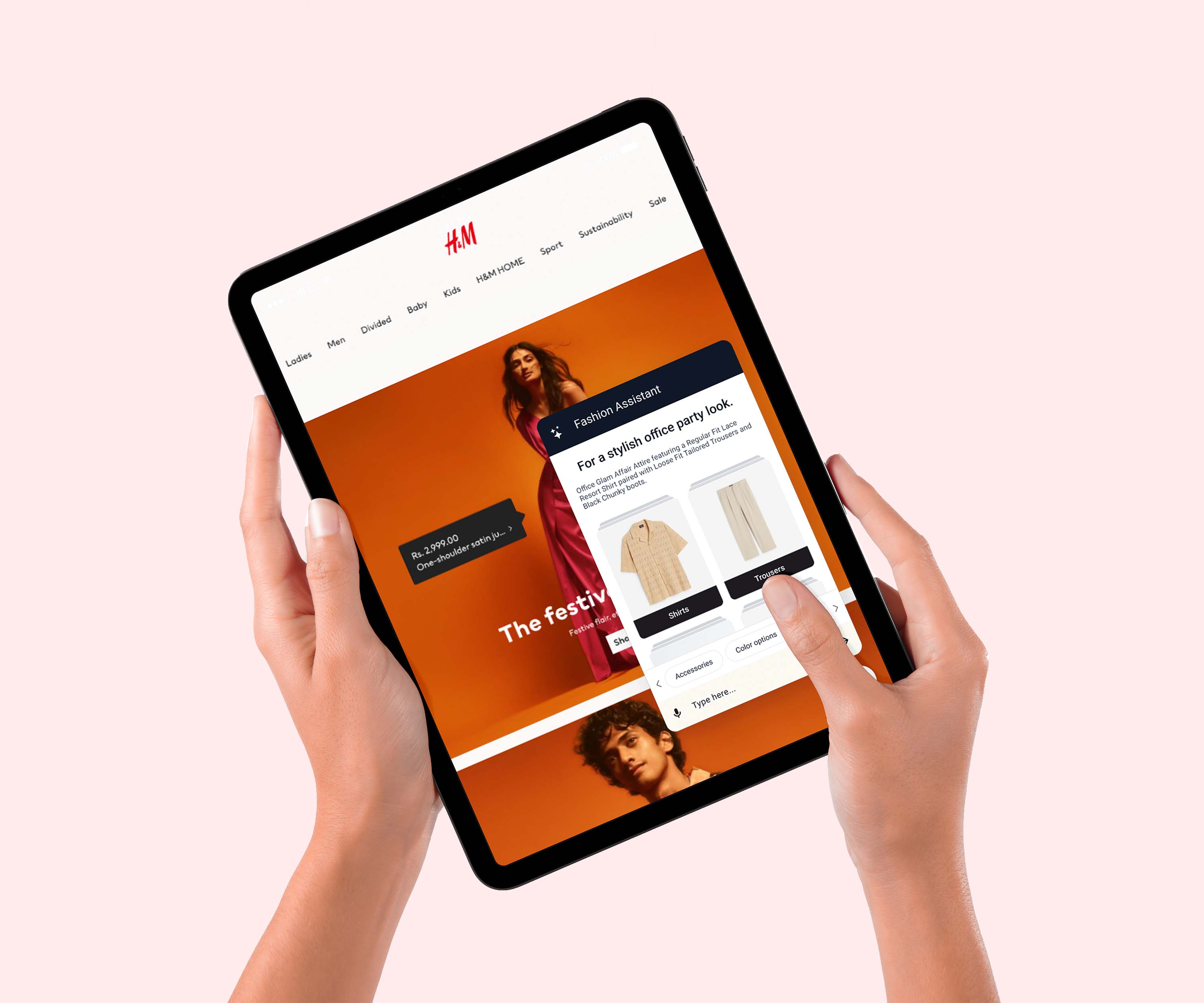
Importance of good data for training classifiers
The need for quality, accurate, complete, and relevant data begins early in the machine learning process. Only if the algorithm is given enough training data can it easily pick up features and find the relationships needed to make predictions down the line.
So, quality training data is the most significant aspect of machine learning and artificial intelligence.
What is Training data:
Training data can include text, images, audio, clicks, video, etc. For instance, a self-driving car model often uses videos and pictures to identify people, roads, and cars. Training data is mainly responsible for the below-mentioned tasks.
This data can be labeled or unlabeled. The challenge is to gather data to cover all possible scenarios. And if it is labeled data that you are using one needs to get the data tagged with relevant labels.
Let’s take a simple example. Let’s revisit how we learned in kindergarten. If you want to teach a child what an apple is, we need to show them all the varieties of apples (red ones, green ones, big ones and small ones and so on) and tell them that they are all apples. This is labeled training data. The child learns from this and the next time we show him an apple he says “apple”. But suppose we show him a pear that looks very similar to an apple, the child may be confused. This confusion leads to a reduction in the accuracy of identifying it like an apple. But over time the child learns and does not make the same mistake.
Unlabeled data is when we show the system all the images relevant to that scenario but we do not label the images as belonging to a specific scenario. The system extracts similarity on its own and clubs similar data together. You need a large quantity of unlabeled data for the systems to see patterns and make accurate predictions.
The types of data training
Supervised learning
This uses labeled data sets. This needs relevant, accurate, complete, and relevant information at the beginning of the learning process. If the algorithm is given the right training information, it can easily find the shapes and see the connections needed to make predictions down the line.
More precisely, quality teaching records are more relevant than any other aspect of machine learning (and technical skills). You set it up for accuracy and success if you introduce machine learning (ML) algorithms with accurate data.
Unsupervised learning
As a machine learning strategy, the unsupervised learning model functions independently without information and patterns identified previously. The model works with unlabeled data, and no user needs to supervise the work methods. The users can focus on more complex processing methods, while the learning algorithms work on neural networks, anomaly detection, clustering, etc.
Now, let’s take a look at what a “Classifier” is in Machine Learning.
A classifier is an algorithm responsible for categorizing the data into multiple segments. These algorithms help machines find patterns, compare data and calculate accurate predictions without human interruption. For example, an email classifier scans your emails and filters them as spam or not spam. At Streamoid we use Classifiers to identify fashion garments, Categories, Physical attributes, Aesthetic attributes, and so on.
Machine learning algorithms are helpful to automate the work that previously was done manually. Machine learning tools work faster and more accurately than humans in specific scenarios. Once they are trained to the accuracy required, they can scale endlessly. They optimize processes, increase efficiencies and save business organizations considerable money and time.
A quick peek at different types of classifiers
There are different types of classifiers that one can choose from based on the kind of problem one is solving. This may seem a bit technical but it gives a comprehensive overview.
Perceptron
Perceptron is a single-layer neural network that is a key component of binary classifiers.
It has four components:
- Input values
- Weight and bias
- Net sum
- Activation function
A perceptron works by taking in numerical inputs, weights, and biases. Once this information is inputted, it multiplies the information with the respective weighted sum. Then the algorithm adds the products together along with the bias. The activation function considers the bias and the weighted sum as inputs and returns the final output.
Naive Bayes
The Naïve Bayes algorithm assumes that each attribute is independent of the other and that all details contribute equally to the result. It assumes that all features are equally significant.
Naïve Bayes requires only a small amount of training data to estimate the necessary parameters. It is significantly faster than other sophisticated and advanced classifications.
It has extensive applications in today's world, such as spam filtering and document classification, etc. However, this particular classifier is notorious for weak inferences because it assumes that all features are equally essential, which is invalid in most real-world situations.
Decision Tree
A Decision Tree is a supervised learning algorithm used for regression and classification problems. The algorithm uses training data to create rules that the structure of a tree can represent.
Like any other tree representation, it has a root node, an internal node, and a leaf node. The internal node represents the condition on the attributes, the branches represent the results of the situation, and the leaf node represents the class label.
To reach the classification, you start from the root node and work your way down to the leaf node, following the if-else style rules. Decision trees can work with both classified and numerical data. This is in contrast to other machine learning algorithms that cannot work with classified data and require encoding to numeric values.

Logistic Regression
A logistic regression model is a supervised classification algorithm that targets variables and takes only discrete values for a given bunch of features. This is used primarily for classification problems and instead of giving 1/0 output it provides probabilistic values which lie in-between.
K-Nearest Neighbor
It is one of the simplest supervised classification algorithms. It does not make assumptions about the underlying data and looks primarily for similarity to classify new data. This algorithm does not learn from the data. In the training phase, it just stores the datasets in different categories and when it gets updated data, it classifies that data into the most similar category.
Now that we have an idea of what classifiers are and the data that factors into building the classifiers. It is time to look at how we can evaluate them
Evaluation of a classifier
Classifiers work best on familiar data sets. As new data comes in, they learn and get more accurate and better. Building a classifier is an iterative method. One needs to constantly evaluate the accuracy and figure out what kind of data to input can improve it.
Cross-validation method
Cross-validation
The data set is split into multiple subsets. One sub-set is used as a test set and the remaining is used for training. This is repeated like a round-robin match till all subsets have been utilized as a test set.

Holdout method
The holdout method is the easiest way to evaluate a ranking. In this method, the data set is split into two groups a training data set and a test data set. Models are trained using the training data set and their accuracy is tested against the test data set.
So, in conclusion, if you introduce machine learning (ML) algorithms to accurate data, you set them up for accuracy and success. This is easier said than done. Finding images to cover all varieties and scenarios in the numbers required for machine learning can be a big challenge. To accurately label them after finding the image presents another set of challenges.
The self-learning systems of course improve over time, but if we want the solution now, then good data is the key.

Importance of Product Taxonomy: Role of AI in Automating & Improving Taxonomies